CEPH Unified Storage, Simplified!
CEPH Unified Storage, Simplified!
In todays era of the data dictating the dynamics of the applications, solving usecases of mobility and scale for the interconnected digital world, data storage is becoming a challenge for those who just keep relying on the legacy storage approaches and solutions that maintain silos of file systems, object storage ( read, file servers) and block storage systems. Most of the organizations thus forgot to Innovate since innovation demands reinvesting in the completely new set of hardware and network gear without guaranteed inter-operatability and the lock-in of the existing legacy.
Current storage systems and solutions span over few decades and have been hardwired thus struggling to solve the scalability and inter-operability issues, their performance is directly proportional to adding newer and faster hardware and disk arrays. With the unprecedented growth of data and processing needs these hierarchical systems cause bottlenecks in data storage and retrieval in real time since distributed application and containers demand faster and quicker access to data and demands consistency and partition tolerance thus solving only availability of data via traditional storage systems is no longer works. Since beginning file, object and block storage systems do not talk to each other and are positioned as a separate solution maintaining silos.
The need for a convergence in storage system demands radical approach and should ensure performance, future enhancements, scalability and availability in built, all these factors directly impact the functioning of the effective and efficient storage system that is should solve the evident problems of the legacy isolated storage solutions. It is thus prudent to have these essential features as part of single unified design rather than addons, The Silver bullet for solving all these storage problems is CEPH…
An open source ( read, free to use) ceph implements object storage on a single distributed cluster, and provides interfaces for object-, block- and file-level storage. Ceph aims primarily for completely distributed operation without a single point of failure, scalable to the exabyte level, and freely available, says Wikipedia.
Background
Ceph is an open source, reliable and easy-to-manage, next-generation distributed object store based storage platform that provides different interfaces for the storage of unstructured data from applications and pools in the various storage resources as a unified system. Developed at University of California, Santa Cruz, by Sage Weil in 2003 as a part of his PhD project, the name "Ceph" is an abbreviation of "cephalopod", a class of molluscs that includes the octopus. The name (emphasized by the logo) suggests the highly parallel behavior of an octopus.
In 2012, Sage Weil created Inktank Storage for professional services and support for Ceph. In October 2015, the Ceph Community Advisory Board was formed to assist the community in driving the direction of open source software-defined storage technology. The charter advisory board includes Ceph community members from global IT organizations that are committed to the Ceph project, including individuals from Canonical, CERN, Cisco, Fujitsu, Intel, Red Hat, SanDisk, and SUSE.
Advantages

- Ceph is the best example of software-defined storage (SDS) analogous to the principles of cloud computing and real time on demand resource pooling
- Ceph scales out using commodity hardware, considering the challenges of scaling up. This helps us define different hardware for different workloads and manage multiple nodes as a single entity.
- With distributed storage, Ceph allows the distribution of the load, which delivers the best possible performance from low cost devices.
- All this contributes to low cost hardware, high data efficiency, broader storage use cases and greater performance.
- ceph replicates the data thus ensuring high redundancy by design, it is a self healing and self-managing system that runs on any commodity hardware thus helping organizations get maximum returns on their hardware and lowers the cost of acquisition and scaling economically.
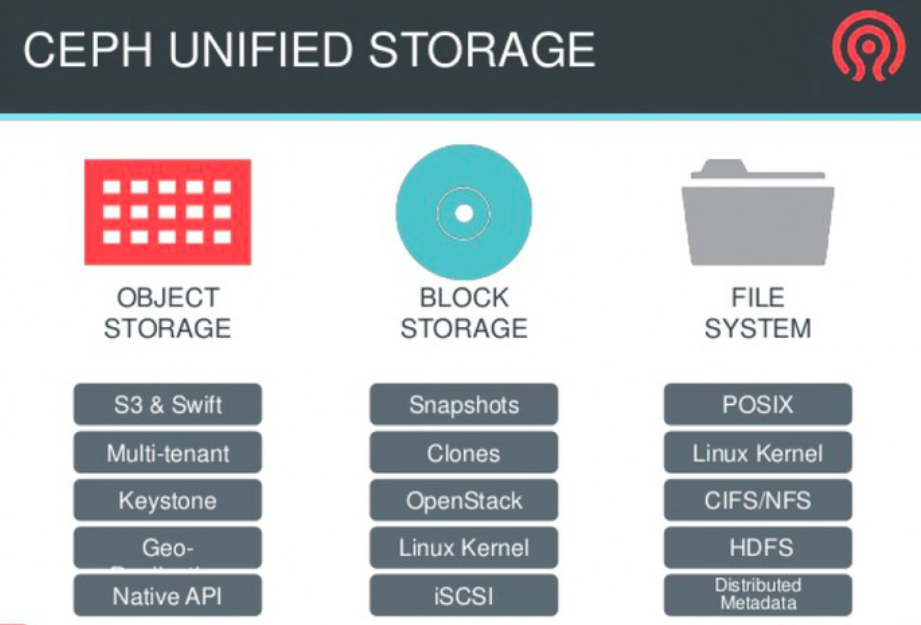
- since it has many features by design to accommodate file system, object and block storage this makes it unique and unified.
Understanding Ceph
The Ceph ecosystem can be broadly divided into four segments (see Figure 1): clients (users of the data), metadata servers (which cache and synchronize the distributed metadata), an object storage cluster (which stores both data and metadata as objects and implements other key responsibilities), and finally the cluster monitors (which implement the monitoring functions). One of the key differences between Ceph and traditional file systems is that rather than focusing the intelligence in the file system itself, the intelligence is distributed around the ecosystem.
Ceph key components & daemons
A high-level component view of a ceph system provides insight into the five key components,
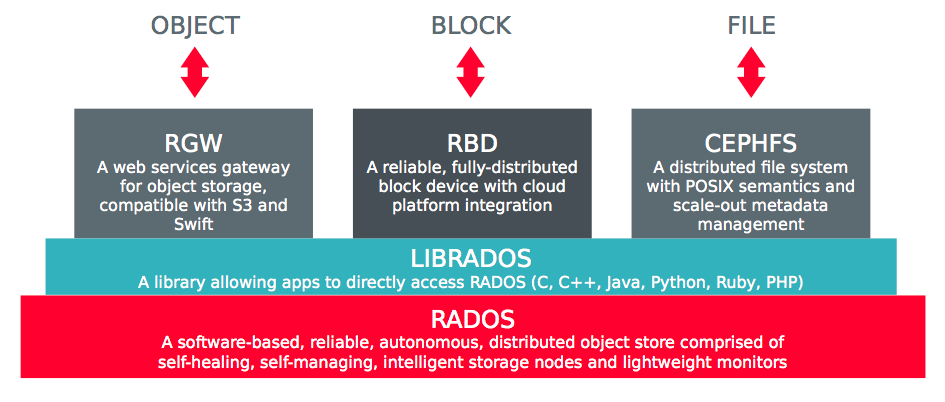
- RADOS- Reliable Autonomic Distributed Object Store is the distributed object store that is self-healing and managing distributed storage nodes. Ceph Storage Clusters consists of two types of daemons: a Ceph OSD Daemon (OSD) that stores data as objects on a storage node; where one node has one OSD daemon running a file store on one storage drive and utilize the CPU, memory and networking of Ceph nodes to perform data replication, erasure coding, rebalancing, recovery, monitoring and reporting functions. Another daemon is Ceph Monitor (MON) that maintains a master copy of the cluster map with the current state of the storage cluster and ensures high consistency using Paxosto ensure agreement about the state of the Ceph Storage cluster. The Ceph Manager daemon (ceph-mgr) runs alongside monitor daemons, to provide additional monitoring and interfaces to external monitoring and management systems. It maintains details about placement groups, process metadata and host metadata in lieu of the Ceph Monitor thus significantly improving performance at scale. The Ceph Manager handles execution of many of the read-only Ceph CLI queries, such as placement group statistics. The Ceph Manager also provides the RESTful monitoring APIs.
- LIBRADOS - allows direct access to RADOS interface for any applications. This helps any application to directly interact with RADOS without any overheads.
- RGW, a web services gateway that sits atop RADOS and enables external API Services talk to LIBRADOS and the RADOS cluster below.
- RBD – a fully distributed block device that integrates with cloud platforms for block storage needs and interacts with LIBRADOS thus any hypervisor can get a direct mount point of the volumes served by LIBRADOS. Ceph block devices are thin-provisioned, resizable and store data striped over multiple OSDs in a Ceph cluster. Ceph block devices leverage RADOS capabilities such as snapshotting, replication and consistency whereas Ceph Object Storage uses the Ceph Object Gateway daemon (radosgw), which is an HTTP server for interacting with a Ceph Storage Cluster. Ceph Object Gateway can store data in the same Ceph Storage Cluster used to store data from Ceph Filesystem clients or Ceph Block Device clients, since they both share a common namespace, one may write data with one API and retrieve it with the other.
- CEPHFS - distributed file system that talks to both block and object storage daemons seamlessly and interacts with OSDs with help of metadata servers and runs the file services over RADOS Cluster.
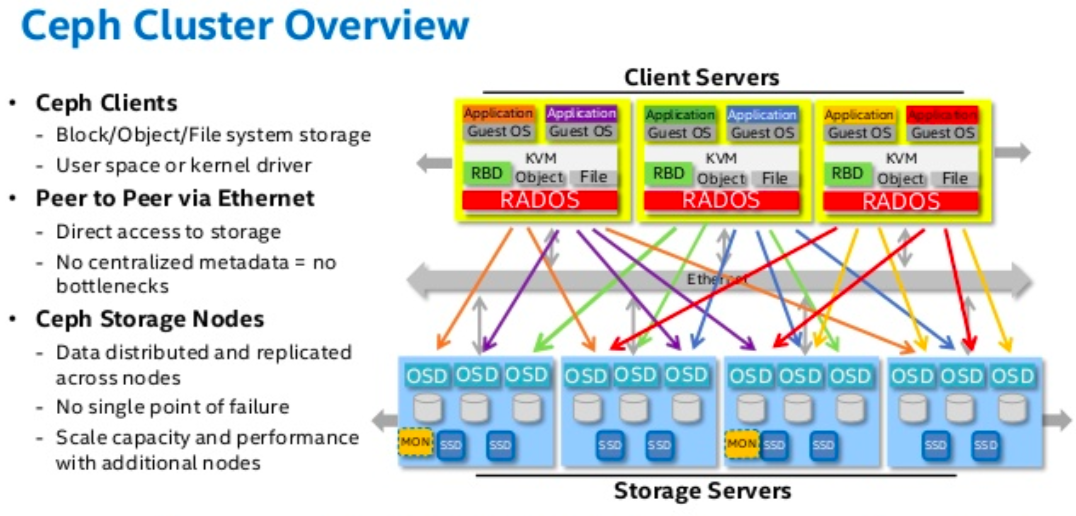
A Ceph Storage Cluster may contain thousands of storage nodes spread across multiple clusters. A minimal system will have at least one Ceph Monitor and two Ceph OSD Daemons for data replication. The Ceph Filesystem, Ceph Object Storage and Ceph Block Devices read data from and write data to the Ceph Storage Cluster.
ceph system thus relies on four key daemons, namely ..ceph-mon, ceph-mds, ceph-osd and ceph-raw.. the function of these helps ceps system, monitor and track what is stored, maintain metadata ( read, data about data) journal the changes and expose the object storage layer as an interface via APIs for ease of integration with ceph clients & thus applications.
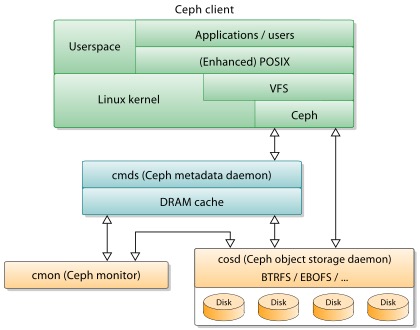
How does Ceph works?
The Ceph Client is the user of the Ceph file system. The Ceph Metadata Daemon provides the metadata services, while the Ceph Object Storage Daemon provides the actual storage (for both data and metadata). Finally, the Ceph Monitor provides cluster management. There can be many Ceph clients, many object storage endpoints, numerous metadata servers (depending on the capacity of the file system), and at least a redundant pair of monitors.
- Monitors: A Ceph Monitor (ceph-mon) maintains maps of the cluster state, including the monitor map, manager map, the OSD map, and the CRUSH map. These maps are critical cluster state required for Ceph daemons to coordinate with each other. Monitors are also responsible for managing authentication between daemons and clients. At least three monitors are normally required for redundancy and high availability.
- Managers: A Ceph Manager daemon (ceph-mgr) is responsible for keeping track of runtime metrics and the current state of the Ceph cluster, including storage utilization, current performance metrics, and system load. The Ceph Manager daemons also host python-based plugins to manage and expose Ceph cluster information, including a web-based Ceph Manager Dashboard and REST API. At least two managers are normally required for high availability.
- Ceph OSDs: A Ceph OSD (object storage daemon, ceph-osd) stores data, handles data replication, recovery, rebalancing, and provides some monitoring information to Ceph Monitors and Managers by checking other Ceph OSD Daemons for a heartbeat. At least 3 Ceph OSDs are normally required for redundancy and high availability.
- MDSs: A Ceph Metadata Server (MDS, ceph-mds) stores metadata on behalf of the Ceph Filesystem (i.e., Ceph Block Devices and Ceph Object Storage do not use MDS). Ceph Metadata Servers allow POSIX file system users to execute basic commands (like ls, find, etc.) without placing an enormous burden on the Ceph Storage Cluster. The job of the metadata server (cmds) is to manage the file system's namespace. Although both metadata and data are stored in the object storage cluster, they are managed separately to support scalability. In fact, metadata is further split among a cluster of metadata servers that can adaptively replicate and distribute the namespace to avoid hot spots
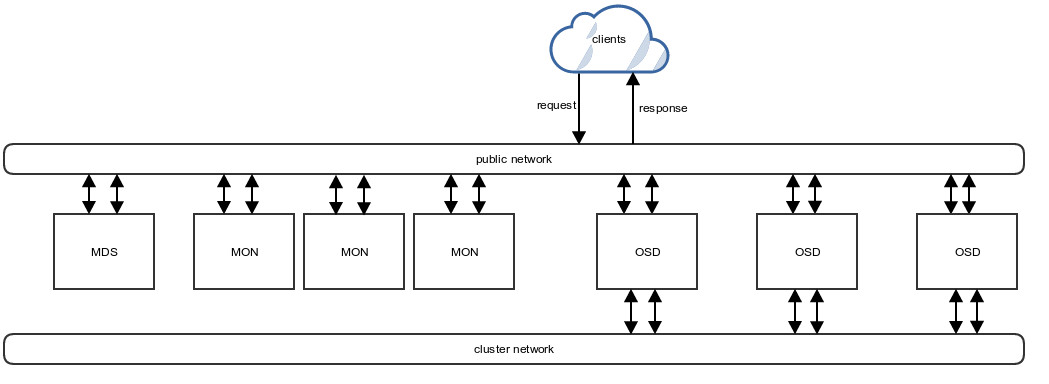
Since all of these daemons are fully distributed and can run on the same set of servers with ability of clients directly interact with all of them makes it agile and adaptive and horizontally scalable storage indeed. A truly A Scalable, High-Performance Distributed File System ensuring performance, reliability, and scalability. Ceph stores data as objects within logical storage pools. Using the CRUSH algorithm, Ceph calculates which placement group should contain the object, and further calculates which Ceph OSD Daemon should store the placement group this enables the Ceph Storage Cluster to scale, rebalance, and recover dynamically.
Ceph divides the OSDs into placement groups for the CRUSH algorithm. These placement groups can be combined together to form a pool, which is like a logical partition for storing the objects in Ceph. Pools can help differentiate between the storage hardware based on performance. Ceph also has cache-tiering, which helps in creating a pool of faster storage devices as cache storage for expensive read/write operations. This helps in improved performance and efficient utilization of the storage hardware. With OpenStack as the cloud platform, Ceph can be used as a Swift object store and Cinder block store utilizing the same storage hardware for multiple needs. Ceph can be used with other cloud platforms like CloudStack, Eucalyptus and OpenNebula.Ceph is thus not only a file system but an object storage ecosystem with enterprise-class features.
Ceph client
User's perspective of Ceph is transparent. From the users' point of view, they have access to a large storage system and are not aware of the underlying metadata servers, monitors, and individual object storage devices that aggregate into a massive storage pool. Users simply see a mount point, from which standard file I/O can be performed. Since with ceph, the file system's intelligence is distributed across the nodes, which simplifies the client interface but also provides Ceph with the ability to massively scale (even dynamically).
The Ceph metadata server
The job of the metadata server (cmds) is to manage the file system's namespace. Even though both metadata and data are stored in the object storage cluster, they are managed separately to support scalability. Metadata is further split among a cluster of metadata servers that can adaptively replicate and distribute the namespace to avoid hot spots and ensure redundancy. As shown below, the metadata servers manage portions of the namespace and can overlap (for redundancy and also for performance). The mapping of metadata servers to namespace is performed in Ceph using dynamic subtree partitioning, which allows Ceph to autonomously adapt to changing workloads (migrating namespaces between metadata servers) while preserving locality for performance and efficiency of read operations
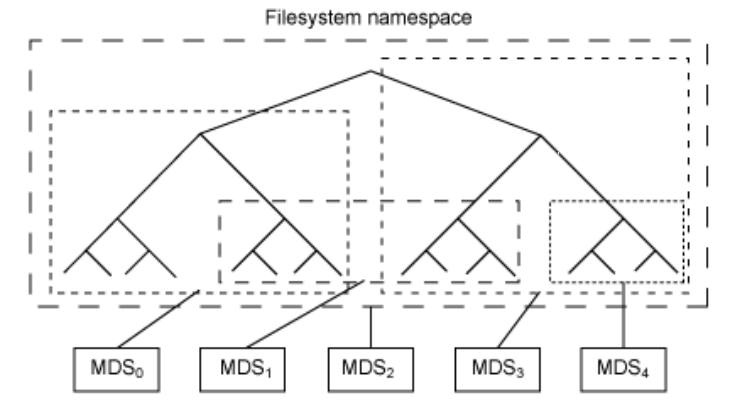
Each metadata server simply manages the namespace for the population of clients, its primary application is an intelligent metadata cache (because actual metadata is eventually stored within the object storage cluster). Metadata to write is cached in a short-term journal, which eventually is pushed to physical storage. This behavior allows the metadata server to serve recent metadata back to clients which is common in metadata operations and provides faster response time for retrieval. The journal is also useful for failure recovery: if the metadata server fails, its journal can be replayed to ensure that metadata is safely stored on the disk. Metadata servers manage the inode space, converting file names to metadata. The metadata server transforms the file name into an inode, file size, and striping data (layout) that the Ceph client uses for file I/O.
Managing Objects in ceph
A file / object is assigned an inode number (INO) from the metadata server, which is a unique identifier. Using the INO and the object number (ONO), each object is assigned an object ID (OID). Using a simple hash over the OID, each object is assigned to a placement group.
The placement group (identified as a PGID) is a conceptual container for all objects. Ceph must handle many types of operations, including data durability via replicas or erasure code chunks, data integrity by scrubbing or CRC checks, replication, rebalancing and recovery. Consequently, managing data on a per-object basis presents a scalability and performance bottleneck. Ceph addresses this bottleneck by sharding a pool into these placement groups.
Finally, the mapping of the placement group to object storage devices is a pseudo-random mapping using an algorithm called Controlled Replication Under Scalable Hashing (CRUSH). The final component for allocation is the cluster map. The cluster map is an efficient representation of the devices representing the storage cluster. With a PGID and the cluster map, ceph can locate any file / object.
Ceph monitors
Ceph includes monitors that implement management of the cluster map, but some elements of fault management are implemented in the object store itself. When object storage devices fail or new devices are added, monitors detect and maintain a valid cluster map. This function is performed in a distributed fashion where map updates are communicated with existing traffic. Ceph uses Paxos, which is a family of algorithms for distributed consensus.
Ceph object storage
Similar to traditional object storage, Ceph storage nodes include not only storage but also intelligence. Traditional drives are simple targets that only respond to commands from initiators. But object storage devices are intelligent devices that act as both targets and initiators to support communication and collaboration with other object storage devices.
The CRUSH Algorithm & Maps
The architecture of Ceph might seem familiar to those who know about Google File System (GFS) and Hadoop Distributed File System (HDFS) but it is also very different from them in multiple ways. Ceph uses CRUSH (controlled, scalable, decentralized placement of replicated data) algorithm for random and distributed data storage among the OSDs. Ceph doesn’t need two round-trips for data retrieval like HDFS or GFS, in which one trip is to the central lookup table to find the data location and the second trip is to the located data node. Every bit of data stored in Ceph OSDs is self-calculated using the CRUSH algorithm and stored independent of any other attribute. When a client requests data from Ceph, this CRUSH algorithm is used to find the exact location of all the requested blocks, and the data is transferred by the responsible OSD nodes. As and when any OSD goes down, a new cluster map is generated in the background and the duplicate data of the crashed OSD is transferred to a new node based on results from the CRUSH algorithm.
Ceph depends upon Ceph Clients and Ceph OSD Daemons having knowledge of the cluster topology, which is inclusive of 5 maps collectively referred to as the “Cluster Map”:
- The Monitor Map: Contains the cluster fsid, the position, name address and port of each monitor. It also indicates the current epoch, when the map was created, and the last time it changed. To view a monitor map, execute ceph mon dump.
- The OSD Map: Contains the cluster fsid, when the map was created and last modified, a list of pools, replica sizes, PG numbers, a list of OSDs and their status (e.g., up, in). To view an OSD map, execute ceph osd dump.
- The PG Map: Contains the PG version, its time stamp, the last OSD map epoch, the full ratios, and details on each placement group such as the PG ID, the Up Set, the Acting Set, the state of the PG (e.g., active + clean), and data usage statistics for each pool.
- The CRUSH Map: Contains a list of storage devices, the failure domain hierarchy (e.g., device, host, rack, row, room, etc.), and rules for traversing the hierarchy when storing data.
- The MDS Map: Contains the current MDS map epoch, when the map was created, and the last time it changed. It also contains the pool for storing metadata, a list of metadata servers, and which metadata servers are up and in. To view an MDS map, execute ceph fs dump.
Each map maintains an iterative history of its operating state changes. Ceph Monitors maintain a master copy of the cluster map including the cluster members, state, changes, and the overall health of the Ceph Storage Cluster.
HIGH AVAILABILITY AUTHENTICATION
To identify users and protect against man-in-the-middle attacks, Ceph provides its cephx authentication system to authenticate users and daemons.Cephx uses shared secret keys for authentication, meaning both the client and the monitor cluster have a copy of the client’s secret key. The authentication protocol is such that both parties are able to prove to each other they have a copy of the key without actually revealing it. This provides mutual authentication, which means the cluster is sure the user possesses the secret key, and the user is sure that the cluster has a copy of the secret key.
A key scalability feature of Ceph is to avoid a centralized interface to the Ceph object store, which means that Ceph clients must be able to interact with OSDs directly. To protect data, Ceph provides its cephx authentication system, which authenticates users operating Ceph clients. The cephx protocol operates in a manner with behavior similar to Kerberos.
Ceph Monitors and OSDs share a secret, so the client can use the ticket provided by the monitor with any OSD or metadata server in the cluster. Like Kerberos, cephx tickets expire, so an attacker cannot use an expired ticket or session key obtained surreptitiously. This form of authentication will prevent attackers with access to the communications medium from either creating bogus messages under another user’s identity or altering another user’s legitimate messages, as long as the user’s secret key is not divulged before it expires.
In nutshell : ceph logical data flow..
The management of data as it flows through a Ceph cluster involves each of the components and coordination among these components empowers Ceph to provide a reliable and robust storage system. Data management begins with clients writing data to pools. When a client writes data to a Ceph pool, the data is sent to the primary OSD. The primary OSD commits the data locally and sends an immediate acknowledgement to the client if replication factor is 1. If the replication factor is greater than 1 (as it should be in any serious deployment) the primary OSD issues write subops to each subsidiary (secondary, tertiary, etc) OSD and awaits a response. depending on the configuration subops ensures multiple copies of data are written to the respective OSDs and metadata is updated subsequently. here is a simplified illustration of ceph logical data flow..
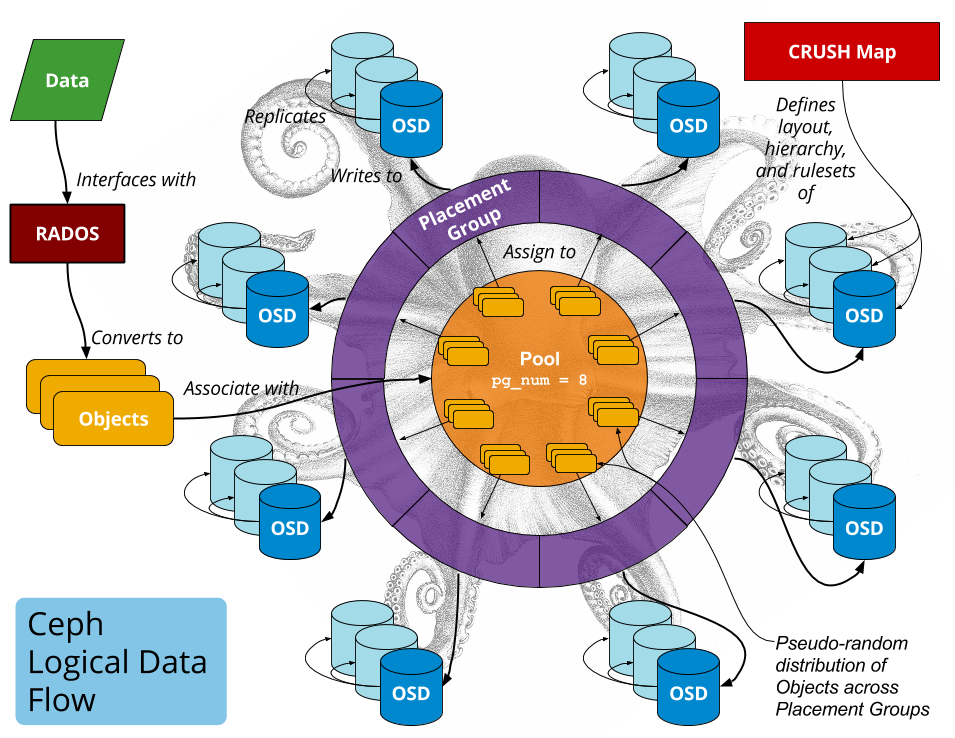
Getting There: Enabling Hyperscale..
Now the primary reason we are going after ceph is scalability, one of the known challenges in scalability is cluster awareness, like in many clustered architectures, the primary purpose of cluster membership is so that a centralized interface knows which nodes it can access. Then the centralized interface provides services to the client through a double dispatch–which is a huge bottleneck at the petabyte-to-exabyte scale to overcome this barrier, ceph’s OSD Daemons and Ceph Clients both are cluster aware by design. Like Ceph clients, each Ceph OSD Daemon knows about other Ceph OSD Daemons in the cluster, this enables Ceph OSD Daemons to interact directly with each other and also with Ceph Monitors. Additionally, it enables Ceph Clients to interact directly with Ceph OSD Daemons thus removing bottleneck.
Key Considerations / Recommendations
- Clock drift and network latency - Ceph is sensitive to clock drift and network latency, therefore it is preferable to install NTP on Ceph nodes, especially on running Ceph Monitors.
- Splitting Placement Groups – to ensure Ceph cluster grows add more OSDs as soon as possible, recovery operations will take longer with a larger number of OSDs and the same number of Placement Groups. Always increase the number of Placement Groups by splitting the existing Placement Groups by updating the corresponding pool’s parameter. The best practice is to increase the number of Placement Groups by small increments.
- Low storage density - By default, Ceph has a replication factor equal to three, meaning that every object is copied on multiple disks. This can be very inefficient in terms of storage density. To reduce the replication factor below three, you can use erasure coding (per pool), preferably combined with SSD-backed caching pools.
- Data locality -In Ceph, the primary OSD serves read and write operations for the given object. Make sure that the primary OSD is located on the same server (in the same rack or the data center) with clients. Ceph allows the primary OSD affinity feature for the same.
- Bucket hierarchy for failure domains - Ceph clusters contain, in the CRUSH (Controlled Replication Under Scalable Hashing) map, a list of all available physical nodes in the cluster and their storage devices. The CRUSH map also contains a definition of the existing infrastructure in terms of hierarchy of buckets. The default buckets are servers, racks, rows and sites. Add more buckets to the hierarchy to reflect your actual infrastructure of a data center or federated data centers also define a custom replication policy based on any of the available buckets defined in the CRUSH map.
- Ceph running full - Space related warnings and errors are reported by ‘ceph -s’ and ‘ceph health’ commands. OSD space is reported by ‘ceph osd df’ command. When an OSD reaches the full threshold (95% by default) it stops accepting write requests, although read requests will be served, you can add more OSDs (or temporary modify the CRUSH map to change the weights for the selected OSDs) to overcome this issue
- OSD outage - Use ‘ceph osd out osdid’ to force the OSD to be ignored for the data placement. Ceph will start replication accordingly to the existing replication policy.
- Lost OSD journal - When an OSD journal fails, all OSDs which use the failed journal should be removed from the cluster.
- Stale Placement Group - When all of the OSDs that have copies of a specific Placement Group are in down and out status, then the Placement Group is marked as stale. Have at least one of the OSDs that have a copy of the affected Placement Group. Recovery will start automatically in this case. If you cannot get at least one OSD, the Placement Group will be lost.
- Ceph Performance relies on many factors, including individual node hardware configuration and the topology of a Ceph cluster. Incorrect or non-optimal configuration will result in slow data/journal reads and writes, unresponsive OSDs, slow backfill and recovery operations.
- Storage - Use separate disks for operating system, OSD data and OSD journals. Ideally use SSD for OSD journal. Use multiple journals per SSD but not more than 5-6 OSDs journals per SSD is a general guideline. Do not run multiple OSDs on a single disk or even running an OSD and a monitor or a metadata server on a single disk. The more OSD nodes you have, the higher overall performance.
- CPU / RAM - do install OSD on the same nodes with other services, such as nova-compute. OSD rebalance, backfill and recovery operations are CPU and RAM intensive, so the whole node may become overloaded and unresponsive.
- Network - Use separate networks for Ceph replication (data replication between OSDs) and client traffic, Ideally a 10GbE network if your budget does not allow 100GbE. It is ideal to have separate logical networks for monitors, controllers and OSDs with adequate redundancy for management network.
Deployment and Hardware Considerations
The ceph deployments can become complex since it offers unified storage and varied options of using the bare-metal, virtualized instances and even public cloud storage buckets are part of the ceph system, there are other options like using ceph as part of Apache Mesos, or even with containers or simply stand-alone ceph cluster. If you already have few high-end servers and wish to build a high performance ceph platform then you must have a deployment strategy as to how will you use CPU, RAM and disks from the bare metal servers and get best of these infra resources in hand.
Best strategy is to map few thumb rules, for every disk on the bare metal server create one corresponding OSD and earmark 1 GB of RAM per TB, similarly for each OSD allocate one CPU thread since RADOS will need lot of processing for data replication, erasure coding, rebalancing, recovery, monitoring and reporting functions running locally one each OSD node. Remember to have different crush maps for different disk types for the high-performance cluster. For a medium or low storage latency clusters minimum hardware requirements are listed in the ceph documentation as hardware recommendation.
In Conclusion, Ceph can do all three types of commonly found storage types (object, block, and file) — a flexibility that separates it from the rest of the SDS herd. It’s inherent scale-out support aligns well with horizontal which means you can gradually build large systems as cost and demand require, and it sports enterprise-grade features such as erasure coding, thin provisioning, cloning, load-balancing, automated tiering between flash and hard drives, and simplified maintenance and debugging. Its Network File System (NFS) interface allows access to the same data from public cloud storage API interferences and NFS file interfaces and is compatible with the Hadoop S3A filesystem client, enabling developers to use Apache Hadoop MapReduce, Hive, and Spark for seamless integration.
While recent acquisition of REDHAT by IBM raised a question about future of ceph, as analysts view advantage of ceph for IBM is that Ceph would provide IBM a truly unified software defined storage platform which is block, file and object storage and thus will provide a wider strategic advantage and brings it closure to open source community for sure.
According to Gartner Inc., Ceph has made successful strategic entry into the enterprise IT storage space and has proved to be the next big evolution in storage technology. With the current adoption rate, Ceph will soon surpass the existing storage solutions at enterprises. There is a lot of development happening with Ceph, which will bring about significant performance improvements to match the current proprietary solutions. Even if you don’t take future enhancements into consideration, Ceph is a storage platform that definitely needs to be looked at for any big deployment that demands data at large scale and proportions and riding high on the software defined storage (SDS) digital transformation curve…