Data Archival-Strategic Importance!

While we continue to discuss, datafication, role of active data and data protection strategies around it, it is imperative to revisit the Data Archival and governance. Most of the businesses today have one way or another to maintain their data archives but in reality, the effectiveness of archival and qualitative approach on archival still stone-age. Don't believe me, let us dwell more and talk about strategy, best practices and techniques deployed for data archival. The topic warrant this discussion due to GDPR and associated impact on organizations who still might be struggling to meet both ends meet! i.e. Governance and BAU ( Read, business as usual) ..
Despite modern distributed databases, concurrency, multi-location, multi-tenant applications and extended CRMs from social media to historical records every tool, application and service is creating massive amount of data and many organizations struggle to even touch the petabytes of data stores actually maintaining records from the beginning of time till date in a single massive datastore. This is primarily due to the way applications are designed and used over years and just changing client facing app servers with modern techniques yet using same datastores used by their unfortunate old cousins.
A system of records (SoR) dictates the 'current' data retrieved from the single source of truth (SSoT) and this comprehensive dataset is sufficient to complete a transaction without reference to offline data sources or dependencies. Your current balance in a bank account, mobile wallet, or even the current level of inventory, or the email you just sent are few examples of "Active data elements" and remain current as long as no other transaction replaces the "values" or the "order of the transaction", as the number of transactions grow these older transactions become passive records and are required only as reference and becomes part of historical information and not required for arriving at "Current" state of the system, as explained earlier. Let us call this dataset as "Current State data" and transactions using them as "Current transactions" for further reference.
All of this active and passive datasets are heavily guarded at the core and if no attempt is made to classify and organize this data in active and archive ready datasets, it becomes monolithic and lowers performance of and transactional system, to make this more complicated any "historical dataset" is regulated by numerous outside entities, each with a say in how long it must be kept, in what format and offsite medias and other governance regulations or statutes and organizations start duplicating this data for offsite and offline storage. However, many IT heads continue to remain unsure about what role governance should play in their data archiving strategy and is the organization taking collective call on regular segregation of active and passive data thus multiple copies of entire dataset is often seen in the official archives.
What is Passive Data, and what is Archival?
As explained above, any data that is not "current state data" and not required to participate in running the "Current" transactions of the application, can be termed as "passive" data. Data which is just reference data, historical records and even comprise of documents as supporting of old transactions etc. In other words, archival data is a "dataset" that is not used, updated or read frequently by the application or sub systems thereof.
This dataset is then moved to low-cost, low performance storage and many times offloaded to offline mode, offsite location and termed as "Archives". The process of identifying passive data, classifying or marked for archival and as a strategy and apply "aging" rules for moving the datasets for target archival facility or storage etc must be defined and is generally governed by the regulatory or statutory requirements of the business / industry vertical or domain. Any and all the data in principle must still remain confidential (Read, encrypted), Retrievable / Readable (Read, Available) and accurate ( read, integrity) even if it resides on offline, offsite and off any connected system, the rules must remain in force. Fundamentally you archive the data that will not change or shouldn't change.
Is Archival same as backup?
 No. The backup is the provision you make to store copy of current dataset on a separate media server (and refreshed / updated via versioning) atleast on daily incremental basis and restored back quickly to maintain the "current state" of the system in case of a disaster towards business continuity and managing service level objectives, on the other hand archival is collection of historical data kept for long term future reference and serves 'offloading' of old datasets, still searchable but slow.. both backups and archives must be guarded safe with encryption, retention policies, granular data selection and in a recoverable form. In fact, it is recommended to have backups in place for archived data.
No. The backup is the provision you make to store copy of current dataset on a separate media server (and refreshed / updated via versioning) atleast on daily incremental basis and restored back quickly to maintain the "current state" of the system in case of a disaster towards business continuity and managing service level objectives, on the other hand archival is collection of historical data kept for long term future reference and serves 'offloading' of old datasets, still searchable but slow.. both backups and archives must be guarded safe with encryption, retention policies, granular data selection and in a recoverable form. In fact, it is recommended to have backups in place for archived data.
What are the basic thumb-rules of Archival?
The Tools and techniques deployed for archival must be able to handle archival from retired/migrated applications, should support data purging, facilitate queries on archival data (this is very important wrt GDPR requirements) and finally must provide standard reports, MIS etc and most importantly user access logs for auditing and access control. Traditionally tapes were used to backup and use as archival but slowly this trend is diminishing with disk-based backups and archival solutions have provided multi-site, multi-copy disk-based storage at an affordable price-point and are now accepted by most of auditors and regulation bodies.
Emergence of "Data protection as a Services" demonstrate the need and capabilities of long term data retention, deduplication, indexing and search, faster restoration, multi copy of the stored objects and rebalancing the multiple copies on multiple disks to safeguard against disk failures etc. additionally these solutions offer thin provisioning, encryption of data at rest and data eraser options ( Read, Media Sanitization, conforms to National Institute of Standards and Technology (NIST) SP 800-88, Guidelines) and multi-tenancy for private cloud for isolation of user specific archives etc. These features are now main stream and must be available in any archival solution in consideration.
Why Archive the data? Benefits?
The most important reason to archive business and transaction data is regulations that mandate archival for data retention. It gives an oversight by providing features such as data monitoring, filtering, and read only access to prevent inappropriate, sensitive, proprietary or other types of content from ever being accessed or modified. On the longer run these archives can be better utilized for building data sets for Big Data & Analytics for trend analysis and build predictive insights etc.
Another great reason to archive is to increase productivity, taking load from transaction applications (Read, databases) and ever-growing amount of content being stored on file servers, improving performance and better user experience for searchability, information requests etc capabilities of historic records for litigation preparation, if in case situations demand so.
What are the legal mandates for Data Protection & Retention?
Archival dataset is still an enterprise asset and is governed by acts and regulations in force, our Information Technology Act, 2000 (Act) has provided the guidance through various sections..
- Section 43-A (Compensation for failure to protect data) primarily deals with compensation for negligence in implementing and maintaining reasonable security practices and procedures in relation to sensitive personal data or information (“SPDI”).
- Section 72-A (Punishment for disclosure of information in breach of lawful contract). deals with personal information and provides punishment for disclosure of information in breach of lawful contract or without the information provider’s consent.
The Ministry of Communications and Information Technology (MCIT) notified the Information Technology (Reasonable Security Practices and Procedures and Sensitive Personal Data or Information) Rules, 2011 (Rules). Further, on 24 August 2011, the MCIT released a press note (Press Note) which clarified a number of provisions of the Rules. Amongst others, the Press Note clarified that the Rules relate to SPDI and are applicable to body corporate (i.e. organization) or any person located in India. The Press Note exempts outsourcing companies in India from the provisions of collection and disclosure, as set out under the Rules.
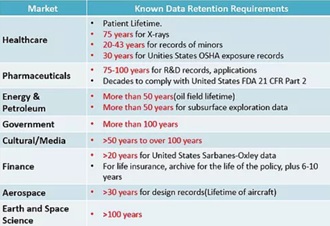 As far as the regulations and laws there are 21 different laws that one must review based on the industry vertical and applicability and draw the conclusions. You don’t need to be a legal expert to remain informed, a simple read of these laws can help you get a perspective on data protection and data retention mandates. I suggest you refer this white paper by MEITY, refer chapter 9 (page 69) & chapter 10 (page 79) to get a quick look at number of prevailing laws that mandate data protection tenets, a great read if you can spare some time for this interesting read. Let me put some breadcrumbs for further reading on this topic ..
As far as the regulations and laws there are 21 different laws that one must review based on the industry vertical and applicability and draw the conclusions. You don’t need to be a legal expert to remain informed, a simple read of these laws can help you get a perspective on data protection and data retention mandates. I suggest you refer this white paper by MEITY, refer chapter 9 (page 69) & chapter 10 (page 79) to get a quick look at number of prevailing laws that mandate data protection tenets, a great read if you can spare some time for this interesting read. Let me put some breadcrumbs for further reading on this topic ..
Information Technology (amendment) Act, 2008
Personal Data Protection Bill 2013
MCIT – Whitepaper on Data protection
Overview of Data Protection Laws in India
Finally, with technology constantly evolving, an approach based on standards would enable the laws to keep pace with rapid changes in technology, as against objective rules that would fail to be relevant with constant technological developments. Here is the draft of the new law tabled in Lok Sabha last year… THE DATA (PRIVACY AND PROTECTION) BILL, 2017, Although drafting such a legislation that is applicable to both the private sector and the Government alike is in itself a daunting task, it may in time gets streamlined for ensuring that all data assets are adequately safeguarded, agree?
What are the things to keep in mind for Archiving?
- Have a Data Archival Strategy and revisit the same for effectiveness – Knowing your data and classifying it is the most important for choosing right solution and identifying dataset for archival. It is important to have block storage and object storage archival as separate processes and toolset; the segregation of structured data and unstructured data has to be handled separately only after understanding the data and its applications and the retention requirements.
- Choice of Technology - This is not a straight forward as it seems, unless you have context of attributes such as type of data, growth and retention period, interoperability and portability across platforms (when technology changes how will you migrate your archives?), destination formats and select media, mounting the archive for search and retrieval, skills and manageability of the solution or tool, unless you opt for fully managed plug & play service from a service provider etc.
- Maintain Multiple Copies.Having multiple copies is a definite safeguard and advisable to remote site, private cloud, and ensuring entire data set is mirrored on multiple disks and devices. As mentioned earlier having backup your entire archive is a must, just because the data is stagnant does not necessarily mean it is obsolete.
- Check Data integrity. Regularly check the integrity of the archived data and retrieval of the same, at times if the archive gets corrupted and remains un-noticed and thus can’t be restored effectively in case of need, thus integrity checks are vital. This should be a well-documented process in your ISMS policy as a separate SOP.
In summary, managing passive data is a great responsibility as it holds the IP of the organization and becomes historical records for various statutes and references. Having a sound strategy to manage archive data will yield better business value and enhances productivity since this dataset has ability to provide you with meaningful business insights.