Data Modeling, Simplified!
A data model is a design for how to structure and represent information driven by the data strategy and thus provides structure and meaning to data.
As a first step a "Data model theory" is coined and then translated into a data model instance. Such model of required information about things in the business or trade, usually with some system, context in mind, further broken in kind of model, classes represent information that must be stored about things or objects in that context. Here is a quick glance into data science and data modeling fitment...

Data Modelling is a process, a critical milestone for organization while embarking journey of Datafication and delivers a strategic goal of specific definition and further analysed for data requirements involving professional data modellers working closely with business stakeholders, thus data model becomes critical reference to all data management and transformation stages, strategies and execution approaches and the process is termed as 'Data Modeling'.
A Data Model is thus...
- Representation of something in ecosystem making use of standards, best practices, context to enable understanding of the concept.
- Describes the specifications, definition and rulesets for data in a business scenario
- Also describes inherent logical structure of the data and the interrelation of datasets within the specific domain and/or vertical and underlying structure of the that domain or vertical
 A conceptual data model further illustrates, attributes and relationships of entities / tenets and not the technical implementation of the same. The data model must represent active references or classification of the dataset or the subject matter.
A conceptual data model further illustrates, attributes and relationships of entities / tenets and not the technical implementation of the same. The data model must represent active references or classification of the dataset or the subject matter.
- The identification - Who - Element is dataset - entities.
- The subjectivity - What, When and Where? The attributes, facts, relationships we want to hold against this data set.
- The objective and outcome - Why and How? The justification or reasoning of the data model and processes, resources deployed to act upon.
This analysis helps build a real data model that provides visibility into entities, attributes and relationship representation in a collective way.
What are the reasons to have a data model?
There could be multiple reasons and desired outcomes to put in place a data model for a specific use case or derive references from existing one, the fundamental need always will be to...
- Capture business requirements, identify and manage redundant data, promote reuse
- Bring the IT and Business stakeholder on a common page of understanding and context, avoid late discovery of facts that might impact process model or strategic objectives
- Ensure reusability analysis helps build a real data model that provides visibility into entities, attributes and relationship representation in a collective way.
 Compliments strategic goals to value engineering and simplifying the interactions between systems and acts as a precursor to enterprise system design and digital transformation initiatives
Compliments strategic goals to value engineering and simplifying the interactions between systems and acts as a precursor to enterprise system design and digital transformation initiatives- Impacts digital transformation imperatives from business, information, process and system architectures by large.
The true sense of the data model is always integrated with the DNA of the organization and important to have a focus and clarity around it.
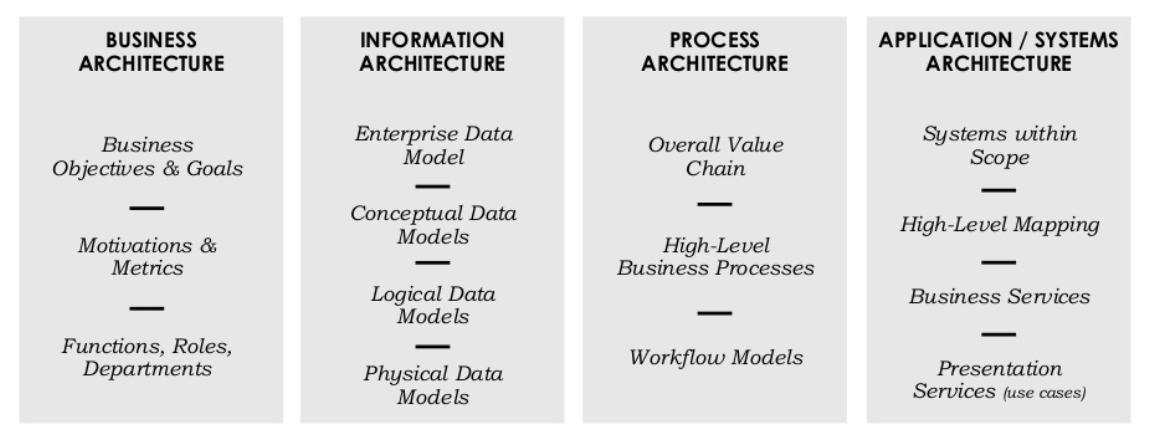
Levels of data models on the data modeling process
 Since the data model is an outcome of the large enterprise information management strategy and key enabler thus touches entire audience to provide big picture thus we call it enterprise data strategy and the instance has these three kinds namely conceptual, logical and physical as per ANSI as defined in 1975.
Since the data model is an outcome of the large enterprise information management strategy and key enabler thus touches entire audience to provide big picture thus we call it enterprise data strategy and the instance has these three kinds namely conceptual, logical and physical as per ANSI as defined in 1975.
This three-schema approach has been well received in software engineering as well while few forums are of the opinion that the enterprise level exist above all these to establish the business use case as a scope statement by sponsors.
- The conceptual level deals with business concepts and defines the interoperations and proof of value to business stakeholders, defines objects and properties and tags the business use cases along. Describes the semantics of an organization and represents a series of assertions about its nature (says Wikipedia)
- The logical level is all about definition, classification, relationships and detailing of the sources, structures, representation and methods of datafication. It is by far the critical input for physical design
- The physical level translates all above into reality by stitching the technicalities of the systems and solutions, implementation and maintenance of the entire ecosystem around to achieve the desires results and provide feedback for continuous improvement
Once data model is in place it can further be normalized to remove redundant datasets, ensure data integrity, make it generally available for multiple data mining needs, maintain the quality and keeping it current.
Requirements for Data Models
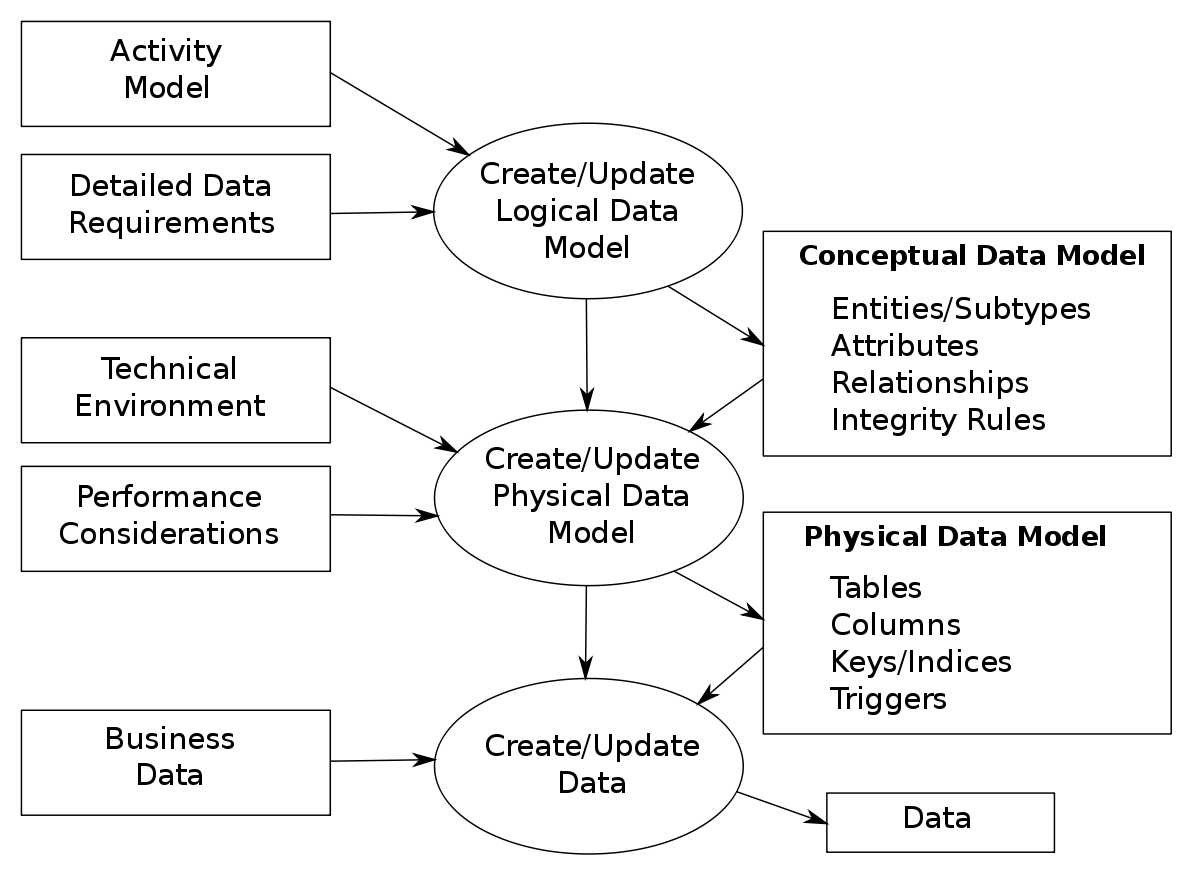
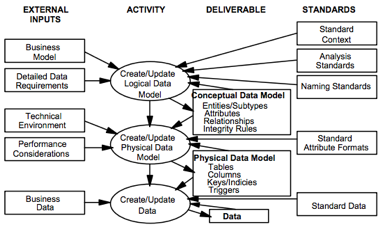 All data models have a context and scope, although they may not be formally defined. The context of a data model is the range within which it is valid, whilst the scope of a model is what it contains. A problem that often arises is that when there is a change in business requirements due to market, regulatory or organizational dynamics, the addition in scope to the model takes it outside the original context
All data models have a context and scope, although they may not be formally defined. The context of a data model is the range within which it is valid, whilst the scope of a model is what it contains. A problem that often arises is that when there is a change in business requirements due to market, regulatory or organizational dynamics, the addition in scope to the model takes it outside the original context
Since there is not set standards for data modeling, here are few requirements in principle that every data model should follow...
- Meet the data requirement, and should be able to build it quick
- be clear and unambiguous to all (not just the authors), keep it simple
- be stable in the face of changing data requirements,
- be flexible in the face of changing business practices,
- be reusable by others,
- be consistent with other models covering the same scope, and
- be able to reconcile conflicting data models
More about Entities, Attributes and Relationships...
Data modeling is either a top-down or bottom up process. In the top down process data model is derived from an intimate understanding of the business and in bottom up process it is derived by reviewing specifications and business documents, in either case it remain a basic model, representing entities and relationships, is developed first to help visualize the model. Then detailing is done to the model by including information about attributes and business rules. There are different approaches, yet everything revolves around three key tenets, which are Entities, Attributes and Relationships. However, an effective data model must completely and accurately represent the data requirements of the stakeholders (Read, end users)
Entities contain descriptive information, entities are objects which contain descriptive information. If a data object has been identified and is described by other objects, then it is an entity. However, an entity is a "thing", "concept" or, object" by large yet entities can sometimes represent the relationships between two or more data objects is known as an associative entity.
Attributes either identify or describe entities, they are data objects that either identify or describe entities. Attributes that identify entities are called key attributes and have values that are atomic (Rad, present a single fact.)
Relationships are associations between entities, Typically, a relationship is indicated by a verb connecting two or more entities like "a customer and his bank account", and further should be classified in terms of cardinality, optionality, direction, and dependence. Cardinality quantifies the relationships and associates multiple entities such have "a customer has two accounts" wherein it also enforces mandatory one relationship i.e. " a customer must have at least one account" etc. point to remember is that the relationship can be "one-to-one", "one-to-many" or "many-to-many" depending on the context in with the data model is rested.
Diving bit deeper, Complex relationships are classified as ternary, an association among three entities and must be replaced by an association entity and the original entities are related to this new entity to simplify the implementation, i.e. this is the job of the data modeller and analysts working together in tandem. This is resolved via introducing "Keys" that tie the different entities together of making it ease and remain contextual.
Validating the Keys and Relationships is a Basic hygiene to be followed and three rules ( Read, Constraints) governing the identification and migration of primary keys must be enforced such as...
- The "Mandate rule" states that every entity shall have a primary key whose values uniquely identify entity instances and the primary key attribute cannot be optional (i.e., have null values).
- As a "No Repeat Rule" The primary key cannot have repeating values, in absence of this control indexing cannot be done and objects cannot be traced thus, the attribute may not have more than one value at a time for a given entity instance is prohibited. Also any two entities should not have identical primary keys with the exception of entities within generalization hierarchies.
- While "Smallest Key Rule" states that the entities with compound primary keys cannot be split into multiple entities with simpler primary keys to avoid the confusion. The entire primary key must migrate from parent entities to child entities and from super type, generic entities, to subtypes, category entities to maintain the integrity of relationship characteristic. In such cases a foreign key is introduced as an attribute that completes a relationship by identifying the parent entity. And provide a method for maintaining referential integrity.
In a nutshell, primary and foreign keys are vital components on which relational theory of data model is rested. Each entity must have an attribute or attributes, the primary key, whose values uniquely identify each instance of the entity. Every child entity must have an attribute, the foreign key, that completes the association with the parent entity and provides linear association. This helps build a generalization hierarchy for structured grouping of entities that share common attributes while preserving their respective differences.
Data Model integration with Process Model
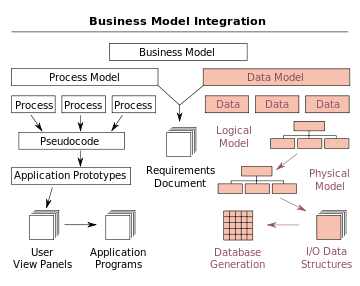 In the context of business process integration, data modeling complements business process modeling, and ultimately results in proof of value. The tenets must co-exist and well-orchestrated for the synergy and balance. Process modeling or specifically Business Process Modeling (BPM) involves representing processes of an enterprise such that the existing processes could be analyzed to improve quality and efficiency. BPM is generally a diagrammatic representation of the sequence of activities or workflows carried out in an organization. It displays the events, actions and connection points from start to the end of the sequence used to improve the efficiency and the quality of the business process. The difference being data model focuses on data objects and assets and process model focuses on functional primitive, processes and activities or tasks thereof.
In the context of business process integration, data modeling complements business process modeling, and ultimately results in proof of value. The tenets must co-exist and well-orchestrated for the synergy and balance. Process modeling or specifically Business Process Modeling (BPM) involves representing processes of an enterprise such that the existing processes could be analyzed to improve quality and efficiency. BPM is generally a diagrammatic representation of the sequence of activities or workflows carried out in an organization. It displays the events, actions and connection points from start to the end of the sequence used to improve the efficiency and the quality of the business process. The difference being data model focuses on data objects and assets and process model focuses on functional primitive, processes and activities or tasks thereof.
A data flow diagram can be a good example of integrated outcome of both data and process model, it however does not show the program logic or processing steps it only limits on describing what system does rather than how it does it. Second step of deliverables is a set of entries about data objects to be stored in repository or project dictionary. This Repository links data, process and logic models of an information system. Data elements that are included in the DFD must appear in the data model and visa versa. Each data store in a process model must relate to business objects represented in the data model. A quick glance at the approaches on the different data modeling methodologies might include:
- Flat Model - single, two-dimensional array of data elements
- Hierarchical Model - records containing fields and sets defining a parent/child hierarchy
- Network Model - similar to hierarchical model allowing one-to-many relationships using a junction 'link' table mapping
- Relational Model - collection of predicates over finite set of predicate variables defined with constraints on the possible values and combination of values
- Star Schema Model - normalized fact and dimension tables removing low cardinality attributes for data aggregations
- Data Vault Model - records long term historical data from multiple data sources using hub, satellite, and link tables

In Conclusion, without a data modeling exercise enterprise data fails to provide business value, and in some cases impede business success through inaccuracy, misuse, or misunderstanding. Having a well-defined Data Modeling as a best practice accelerates and augments the business value of data.