Database Evolution Simplified

Database Evolution Simplified
Rajesh Dangi, Mar 2021
Databases are the core elements of any application environment, like the distributed applications, they too keep evolving to solve the fundamentals like availability and integrity of data and keep running under any adverse situations. Not so long ago that we have had the BCP/DR documents mentioning the terminologies like failover, fallback, primary, secondary databases, and log shipping, etc.
All of these were nightmare words for database administrators. In case of an eventuality that plays out a disaster, they have to work round the clock to get their databases, indexes, and logs to a running state without loss of any data. This would take from a few minutes to many hours or even a few days. The database OEMs vendors then became creative and build ancillary products or features that held were sold to help users protect their data against such situations to help faster database recoveries, etc.
Evolution of database systems
The history of databases from the 1960s with the emergence of multi-disk systems used by private enterprises mentions the creation of general-purpose databases and data models resting on CODASYL, a network data model with basic DDL and DML operations for famous COBOL language extensions for processing collections of records, the modern era started evolving actually in 1970s when the concepts of relational databases stared emerging and finally in 1980s we saw a flood of SQL ( Read, Structured query languages) started establishing their presence.
The introduction of IBM PC ( Read, Personal Computer) paved the way for many databases such as Ingres Corp., MS SQL Server, Sybase, PARADOX, RBASE 5000, RIM, Dbase III and IV, OS/2, and Watcom SQL, to name a few. The story started unfolding as most of these databases started adding new features and capabilities to store many datatypes apart from numbers and characters. None of these have had any clue on the single point of failures and database recoveries as built-in features apart from reindexing in case of new record additions. In 1988 several vendors, mostly from the Unix and database communities, formed the SQL Access Group (SAG) as a collective effort to document a single basic standard for the SQL language. Of course, MSFT and Oracle continued their fore independently and started establishing their database system in the large consumer base of enterprise customers.
Only in the 1990s that the client-server architecture dictated the databases to provide ODBC as standard API access over the network and fostered the centralized database concept. The OLTP ( Read, Online transaction processing) system laid the foundation for internet database connectors, such as FrontPage, Active Server Pages, Java Servlets, EJB ( Read, Enterprise Java Beans), ColdFusion, and Oracle Developer 2000. An exciting era of open source solutions started unfolding with the use of Apache, CGI, GCC & MySQL.
The Programmers and designers began to treat the data in their databases as objects and attribute the data as metadata during this era. The relations between data to objects and their attributes and not to individual fields, this approach paved way for differentiation between Object databases and object-relational databases. The object-oriented language (Read, Extensions to SQL) that developers started using as an alternative to purely relational SQL. On the programming side, libraries are known as object-relational mappings (ORMs) and XML Databases laid the foundation for this new cult.
As mentioned earlier, the critical link between the evolution of programming languages from coding binary sequences to procedural languages (e.g. Cobol, Fortran, and Pascal), functional programming languages (e.g. APE and ML), object-oriented languages (e.g. C++, and Java), commercial 4GLs (Open Ingres, Informix 4GL, etc) started some degree of user-level abstraction. The persistent data structures also kept evolving from sequential files to structured files, network databases, hierarchical databases, RDBMS, and further into ORDBMS and OODBMS offering more controlled and flexible storage, interface, and transactional capabilities having complex objects and structures as part of their design.
The emergence of NO-SQL databases
By the late 2000s, the terms big data, real-time applications started flooding the internet, and in early 2009 "open-source distributed, non-relational databases" attempted to label the emergence of an increasing number of non-relational, distributed data stores, including open-source clones of Bigtable/MapReduce, etc. The NoSQL was now the official standard database type that stored data in JSON ( Read, JavaScript Object Notation) documents instead of columns and rows used by relational databases. This was a major paradigm shift for paving the way to modern databases that by design had real-time data management to accommodate unprecedented levels of scale, speed, and data variability.
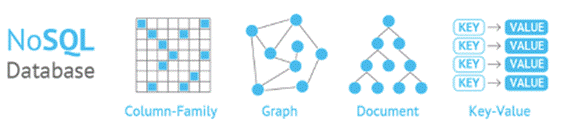
Type of NoSQL databases can be classified into four types, although every category has its unique attributes and limitations and applied for specific use cases providing more options to the developers.
● Key-value databases used for collection, associative arrays, etc. Key-value stores help to store schema-less data in a large volume of reads, writes, and can do horizontal scaling at scales that other types of databases cannot achieve in real-time. ( Eg. Redis, Dynamo, Riak etc)
● Document-Oriented NoSQL DB stores and retrieves data as Key-value pairs, but the value part is stored as a document in JSON or XML formats making CMS and content platforms, e-commerce applications, more agile enriching performance ( Eg.CouchDB, MongoDB, Riak, etc). Although Key-value and Document databases are almost similar since in Key-value, a value is a document but the structure of the Document is opaque whereas in Document databases, the Document ID is the key, but the Document’s structure is often exposed and used for querying.
● A Graph type database stores entities as well the relations amongst those entities that are stored as a node with the relationship as edges. An edge references the relationship between nodes with a unique identifier very well-tuned for social media, logistics, spatial data, etc use cases. ( Eg. Neo4J, Infinite Graph, OrientDB, FlockDB, etc)
● The Column-oriented databases have structured columns and are based on BigTable paper by Google. Column databases store each row separately, allowing for quicker scans when only a small number of rows are involved. Typical use-cases are data warehouses, business intelligence, CRM, etc. ( e.g. Cassandra, Druid, HBase, Vertica, etc.) Interestingly, HBase is a wide-column store and has been widely adopted because of its lineage with Hadoop and HDFS. HBase runs on top of HDFS and is well-suited for faster read and write operations on large datasets with high throughput and low input/output latency. Apache Trafodion project provides a SQL query engine with ODBC and JDBC drivers and distributed ACID transaction protection across multiple statements, tables, and rows that use HBase as a storage engine.
The Ledger Databases
This is the emerging trend of the new offshoot that is specialized based on the blockchain ledgers principles. This database has a key insight that it remembers the past. New information doesn’t overwrite the existing record/data but is instead added to it. The log is the heart of the database and the source of truth, not the tables. Each update is appended to the log as a new entry thus each transaction is immutable and transparent to have access to the past. (Read, The log’s information is fully quarriable) and thus verifiable. Likes of a blockchain ledger technology that provides for the immutability of transactions as an inbuilt feature of the ledger database. MongoDB 4.0, is on the right path to offering enterprises a way to take advantage of ledger-like technology without the complexities. Typically most blockchains cannot process more than 15 transactions per second, these ledger databases are gearing up to optimize performance to handle transactions at scale and can significantly disrupt the rest of the industry.
Modern Relational Databases - NewSQLs
The dynamics of traditional relational database frameworks also have evolved to keep in line with the dynamics of data surge and real-time processing requirements, systems are measured against, of course, owing to the use case and priorities thereof. Today, the most challenging problem in distributed systems is building a distributed database in order to achieve scalability over many nodes, distributed key-value stores (NoSQL), and make extreme trade-offs on the rich features offered by the traditional relational database management systems (RDBMS), including SQL, joins, foreign keys, and ACID guarantees, etc ( will explain this concept later in this article).
The best of both worlds is attempted by a few modern proven relational yet distributed databases like PostgreSQL, MySQL, etc. These new distributed databases are implementing RDBMS functionality like SQL on top of distributed key-value stores (“NewSQL”) and provide SQL support, query performance, concurrency, indexing, foreign keys, transactions, stored procedures, etc. To top it all they deploy a data sharding mechanism for providing data locale via Citus, an open-source PostgreSQL extension that transparently distributes tables and queries in a way that provides the horizontal scale, but with all the PostgreSQL features that the distributed application requires today.
PostgreSQL has been in the game for several decades now and has incredible code quality, modularity, and extensibility. This extensibility offers a unique opportunity: to transform PostgreSQL into a distributed database, and run at scale competing with some of the fastest NOSQLs.
There are other databases like MySQL, MariaDB, ClustrixDB, etc that are riding the wave in transforming the landscape. ClustrixDB, now owned by MariaDB, is a scale-out, clustered relational HTAP (hybrid transaction/analytical processing) database designed with a shared-nothing architecture.
CockroachDB is another example of an open-source, horizontally scalable, distributed PostgreSQL-compatible SQL database that uses a Raft algorithm for reaching a consensus among its nodes and is fault-tolerant by design.
Concept of ACID and CAP – Database properties
Today’s web-scale era demands all distributed database systems around scalability, availability, and performance. There are two approaches we must understand that all NoSQL systems are measured against, of course owing to the use case and priorities thereof.
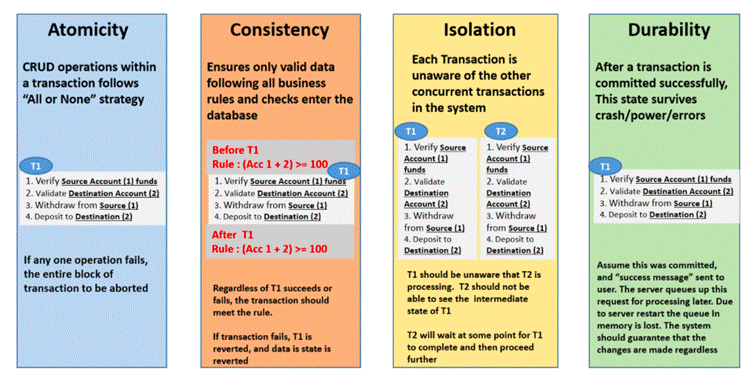
ACID describes a set of properties, database transactions intended to guarantee data validity despite errors, power failures, and other atrocities against which guarantee a database transaction is reliable. NoSQL typically tries to give the developer ability to the trade-off between these choices. ACID stands for,
● Atomicity implies when an update occurs to a database either all or none of the refresh will end up accessible to anyone, thus a transaction and it either submits or aborts in totality.
● Consistency should guarantee that any alternations to values in an instance/data nodes are steady. i.e. any data written to the database must be valid and any transaction that completes will change the state of the database ensuring no transaction can create an invalid data state.
● Isolation is required in the case of simultaneous transactions. Fundamental to achieving concurrency control, isolation ensures that the concurrent execution of transactions results in a system state that would be obtained if transactions were executed serially, i.e., one after the other. With isolation, an incomplete transaction cannot affect another incomplete transaction, an essential idea to understanding isolation through transactions is serializability.
● Durability maintaining updates of conferred transactions are imperative. These updates should never be lost under any situation and the database has the capacity to recover conferred transaction updates if either the system or the capacity media fails or is unavailable. i.e the transaction once committed will persist and will not be undone to accommodate conflicts with other operations.
Practically there will not be any assurance of strong consistency (i.e, the data which is written is not immediately visible to all clients), but in few situations, eventual consistency is good enough. This means the steady-state value of the data object will be consistent.
The CAP, on the other hand, is a theorem that describes how the laws of physics dictate that a distributed system must make a trade-off among desirable characteristics.
● Consistent: All replicas of the same data will be the same value across a distributed system.
● Available: All live nodes in a distributed system can process operations and respond to queries.
● Partition Tolerant: The system is designed to operate in the face of unplanned network connectivity loss between replicas.
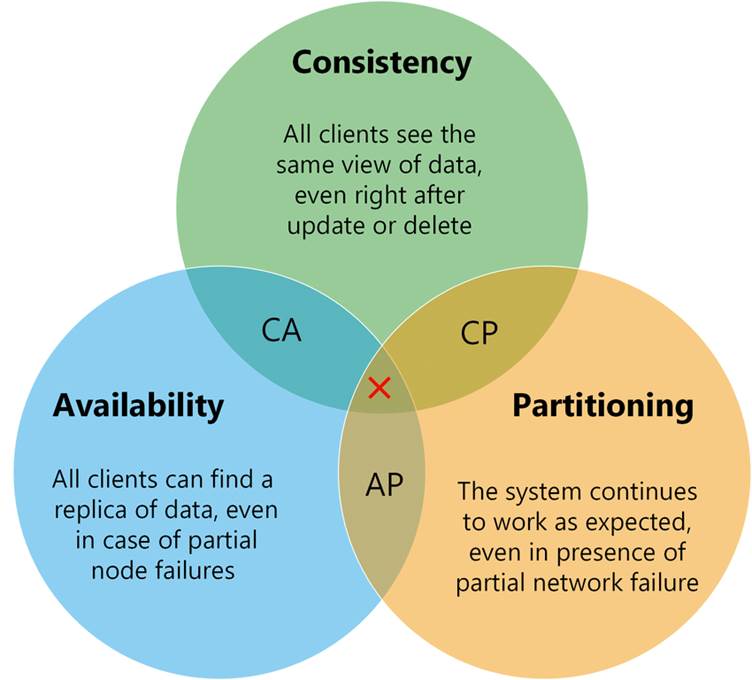
This too looks good on paper but realistically suggests a trade-off on prioritization of the requirements, in reality only two states are possible and practical to achieve.
Traditional RDBMS is very schema-oriented, so it is very useful for structured data, but if you want flexible schema, or the situation requires a fast-changing structure of data, then NoSQL provides ease of handling that in return for consistency or partition tolerance.
In summary, Databases remain a vital component of any system design and with changing times and/or use cases in today’s digital space, dynamics are changing and paving the way to new technologies, data structures, and deployment strategies. There is no silver bullet that exists to solve all the problems and enforce priorities yet an informed choice on data management would go long way enriching user experience and data integrity for the masses. Modern databases are solving the problem statements their erstwhile legacy databases could not achieve or attempted, the race between NoSQL, Distributed RDBMS / NewSQL’s will get more and more competitive as the volume, velocity, veracity, and variability of data will keep scaling higher thresholds keeping the OEM and open source communities on their toes for sure. Isn’t it?
***
Feb 2021. Compilation from various publicly available internet sources, the author’s views are personal.
#NoSQL #NewSQLs #DistributedComputing #RDBMS