Focus on the Fourth of the Big Data for EDH enablement!
Big data as defined in the Wikipedia, Big data is a term for large or complex data sets that are a constantly moving targets for the traditional strategies, tools for processing and managing them via traditional data processing applications which are inadequate to deal with them. Challenges include analysis, capture, data curation, search, sharing, storage, transfer, visualization, querying, updating and information privacy.
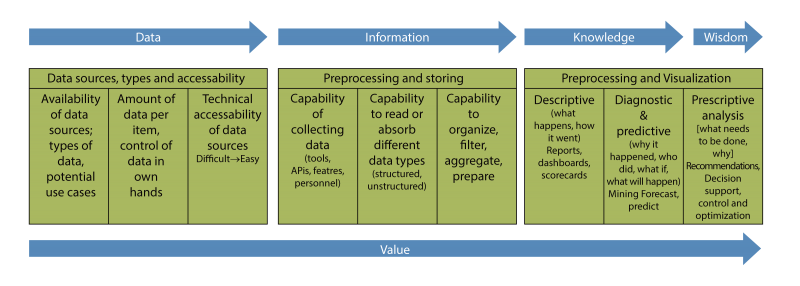
Academically this sounds good as most of the organizations are banking on the data to provide them the insights on their use cases, more predominantly via strategic usage of the infrastructure, tool sets and strategic uses cases that drive presentation layer of the processed data, i.e. information. The process though defined and known is not as simple as stated. Before we dwell upon the challenges let us take a quick read on the four Vs of the big data. i.e.
- Volume - size & scale of data simply put. It is said that bigger the data set better it is for meaningful insights, the volume itself dictated the BIG element of the big data.
- Velocity - Speed of Change or Creation. i.e. Anatomy of Streaming data IoT, Metadata, Social Media from the different sources have a different pace of the incoming data streams that needs to be captured and stored else getting lost in that point of time.
- Variety -which talks about different forms, types i.e. nature of data i.e. structured or unstructured, coming in batches or streams and has no rulesets defined to store and process at the time of creation, remember the term metadata ( i.e. data about the data) etc that makes the bigdata highly complex for traditional computing means
- Veracity -certainty, integrity and inconsistency of data - Veracity is an indication of data integrity and the ability for an organization to trust the data and be able to confidently use it to make crucial decisions.
As you must have gathered that the bigdata is well beyond the defined data sets that traditional systems have dealt with and thus demand a separate handling, farming and processing strategy, if you miss a single thought process that encompasses all the tenets of bigdata the results could be irrelevant and unfit for the business use. This brings us to think about an additional called Value of this initiative
Why search for fifth Value?
Simply put, Data-driven decisions are The decisions. These insightful decisions are the business enablers and rests on the basis of evidence rather than intuition or gut feel there are more tenets as to how data will be defined ( data classification), captured ( Data Ingestion) then normalized ( Data Integration) and then transformed ( Data Visualization & Analytics) to arrive at the Value of the eco system we just described. Few aspects that needs consideration such as..
- Purpose & Constancy of purpose making it relevant and useful to business in shortest time and minimum investment possible, simply is the Use Case we are trying to solve via bigdata still relevant and practical for quick realization and accepts sudden change in the course of data transformation and visualization.
- Revealing Insights Visualization of the insights for conveying the meaning are required yet is the real data science aspect of the exercise. If the algorithms and means and methods used for data transformation are not up-to the mark then the results or yields will be sacrosanct to the desire.
- Single source of truth Does the enterprise data lake or data hub augments data ingestion from all current and future tools, applications to ensure all the Context of the data will liberate multidimensional and respects multiple sources. For example is your CRM listening to social media handles and captures the relevant inputs to arrive at a strategy more relevant to the customer rather than resting the judgment only on a single view.
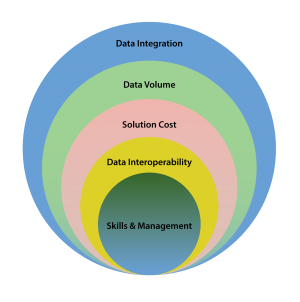
looking at the vastness of these aspects it is more practical to relook at your bigdata strategy and focus on building the Enterprise data hub at the first logical step. There are quite a few advantages to build Single source of truth than relying on the isolated solutions that actually create more data silos in an organization while attempting to deliver Analytics or Dashboards from their native ( read proprietary) platforms locking the data to be used only with or via their platforms. Beyond these aspects there are challenges that too must be dealt with while building the Enterprise Data Hub such as.
- Data Integration With such variety, a related challenge is how to manage and control data quality so that you can meaningfully connect well understood data from your data warehouse with data that is less well understood. A simple way out is to keep the data in Key, Value format for normalization and interpretability by different tools and technologies of data management.
- Data volume The ability to process the volume at an acceptable speed so that the information is available to decision makers when they need it.
- Solution cost To gain value from such vast amount of data it is necessary to process it accurately and with right kind of tools But to ensure a positive ROI and continues use of such tools it is crucial to reduce the solution cost associated in processing such data. There are proven technologies such as private, public or hybrid clouds that can provide solutions for on demand infrastructure bundled with pay as you go licenses for EDH eco system.
- Data Interoperability This perhaps is the biggest challenge for corporates to free up the data from the native platforms, be able to present the same datasets for various project or use cases from variety of different tools. Unless the data is stores and ingested in a central open data lake or enterprise hub enabled by Hadoop etc the data mining and transformation is not liberated from the clutches of the current tools that fade out or outrun by newer / emerging technologies thus limiting the corporates ability to harness the latest and emerging solutions a key to an effective information lifecycle management building and analytical muscle.
- Skills & Management Data is being harnessed with new tools and is being looked at in different ways. There a shortage of people with the skills in big data analytics and help create meaningful insights as a results or conclusion. Unless an ecosystem is invoked a single vendor, single technology or tool might not do the justice thus adding much more complexity to manage the same.
More on Why Enterprise data hub?
We touched upon earlier on the need of having an “Enterprise Data Hub let us gain more insights on the concept and benefits of having one. Since it is complementing the modern data strategy, and enterprise data hub enables collection and storage of unlimited data cost-effectively and reliably respecting diverse set of users, use cases and integrated analytic solutions. The biggest advantages are
Longevity & Sustenance Since the enterprise data hub has been built on the zero data loss and optimized for performance via distributed computing the traditional backups and offsite storage is no longer relevant, the systems such as Hadoop has built in resiliency and fail proof tolerance for processing sets it apart by design rather than external operational ability.
Faster and Agile The data hub has ability to ingest, transform and process the data on the same dataset simultaneously it is limitless and closer to real time storage and analysis making it more relevant for the current scenarios of use cases, truly online.
Availability & Compliance - The agility in the real time processing and storage and zero loss principle complementing archival compliance for internal and external regulatory demands. Since entire data is available for processing without additional overheads the system remains truly reactive to the demands of the business for comprehensive full data set computing, and guaranteed low latency at any scale which seems to be the USP.
Cost effective - Unlike traditional archival storage solutions, the “Enterprise data hub is an online system: all data is available for query or compute this not only accelerate Data Preparation and reduces costs of preparing data processing workloads that previously had to run on expensive systems, now can migrate on a commodity hardware build as you grow and even on cloud, where they run at very low cost, in parallel, much faster than before.